


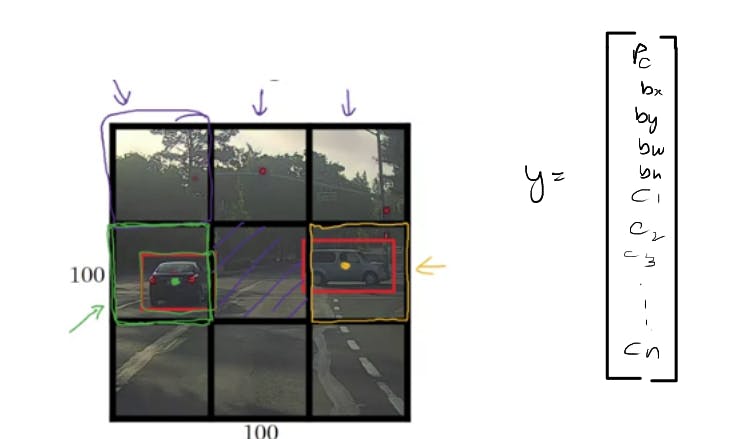
YOLO algorithm takes the midpoint of the objects and then assigns the object to the grid cell containing the midpoint. So the left car is assigned to this grid cell, and the car on the right, which is this midpoint, is assigned to this grid cell. And so even though the central grid cell has some parts of both cars, we'll pretend the central grid cell has no interesting object so that the central grid cell the class label Y also looks like this vector with no object,
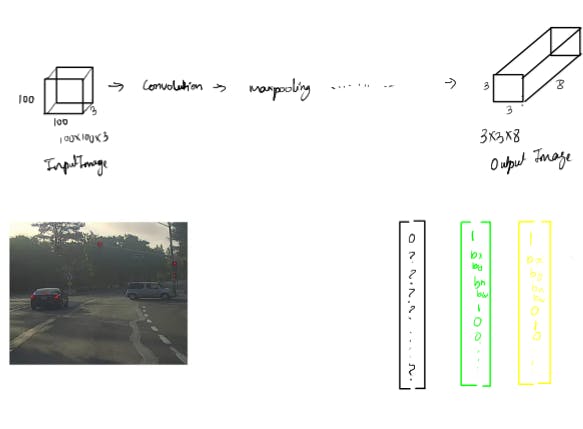
Building the model
- the input is 100x100x3, that's the input image. And then you have a usual convnet with conv layers and max pool layers, and so on. choose the conv layers and the max pool layers so that this eventually maps to a 3x3x8 output volume.
Training the model
- And so what you do is you have an input X, and you have these target labels Y which are 3x3x8, and we use back propagation to train the neural network to map from any input X to this type of output volume Y.
Testing the model
During testing what you do is you feed an input image X and run forward propogation until you get the output Y(which is 3x3x8 volume box) and then for each of the nine outputs of each of the 3x3 positions of the output, you can read off 1 or 0 if there is an object associated with that one of the nine positions.
- If the Pc=1 then we further go through the vector values
- where is the bounding box for the object in that grid cell is determined by the Bx,By,Bw,Bh
- what object it is determined by the the class vectors C1,C2..Cn
Intersection Over Union (IOU)
Object detection aspect is to localize the object so,in YOLO we have a method called IOU
 Let's say your algorithm outputs this bounding box in purple,to decide whether this is a good prediction or not we compare it with the actual bounding box which is shown in red
Let's say your algorithm outputs this bounding box in purple,to decide whether this is a good prediction or not we compare it with the actual bounding box which is shown in red
- red-box =actual bounding box
- purple-box =predicted bounding box So the intersection over union function does, or IoU does, is it computes the intersection over union of these two bounding boxes, so the union of these two bounding boxes is this green area
whereas the intersection is this smaller region here
IOU= Intersection area/Union area
if the IoU >= 0.5 where 0.5 is the threshold.
then the predicted bounding box is a good prediction of the object
else
the predicted bounding box is not a good prediction of the object
more generally, IoU is a measure of the overlap between two bounding boxes. Where if you have two boxes,you can compute the intersection,compute the union, and take the ratio of the two areas. And so this is also a way of measuring how similar two boxes are to each other.
Non max suppression
If the algorithm outputs many bounding boxes for an object this method ensures that for an object it is only formed once.
 In practical scenario we use more number of grid boxes which take the number 19x19 grid.
In practical scenario we use more number of grid boxes which take the number 19x19 grid.
- Technically these two car's has just one midpoint,so it should be assigned to just one grid cell. so technically only one of those grid cells should predict that there is a car.
- In practice, we are running an object classification and localization algorithm for every one of these split cells. So it's possible that this split cell might think that the center of a car is in those indicated points
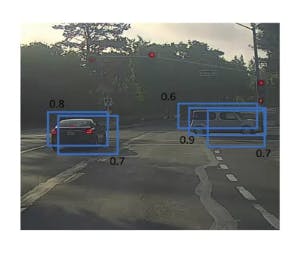 We might end up with multiple detection's of each object. So,non-max suppression cleans up these detection's and end up with just one detection per car.
We might end up with multiple detection's of each object. So,non-max suppression cleans up these detection's and end up with just one detection per car.
It first detects the box with highest value of probability(Pc x P(class detected)) and applies IOU with the overlapping boxes
Apply non max suppression for each of the classes:
Discard all boxes with Pc <= 0.5
While there are remaining boxes:
Pick the box with the largest Pc
Output that as a prediction
if there is overlapping with the current picked box with other predicted boxes
if IOU >=0.5
then the box with highest probability is selected and
get rid of that box
else
each box represents different object
Anchor Boxes
Each grid can detect one object which are presented as the vector,but with this there comes an ambiguity if there's 2 objects with their midpoint lying in the same grid .The output of the grid is not able to output 2 bounding boxes and hence with the idea of anchor boxes we can pre-define two different shapes called anchor box and have class variables be repeated twice to get a vector of size 16 with c1, c2 ,c3 represting three classes
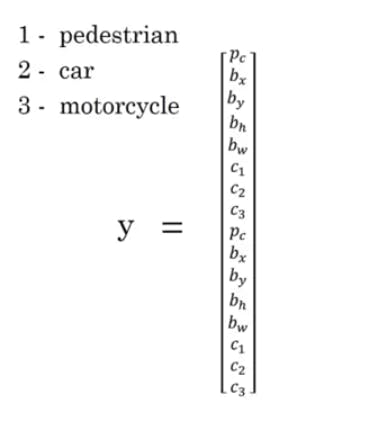 be able to associate two predictions with the two anchor boxes.
be able to associate two predictions with the two anchor boxes.
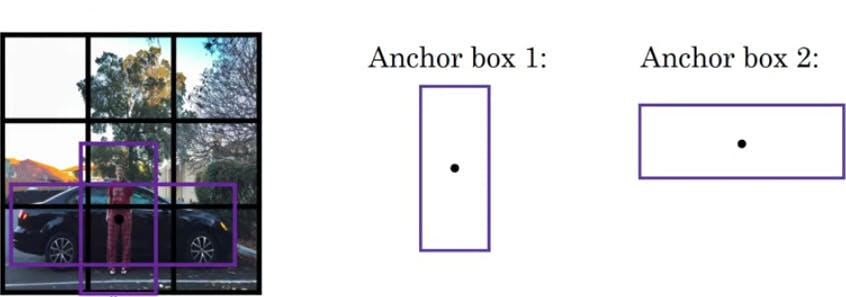
So the image with a grid 3x3 outputs a volume of 3x3x2x8 or just simply 3x3x16
Semantic segmentation with U-Net
The idea behind this algorithm is to take every single pixel and label every single pixel individually with the appropriate class label.

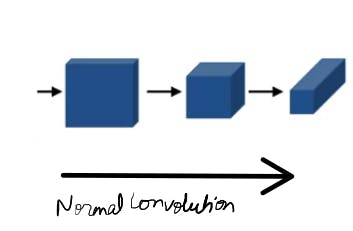 The normal convolution network which is the first half will compress the image
we go from a very large image to smaller height but with greater volume.
So we loose a lot of spatial information because of the dimension cut, but it's much deeper.
The normal convolution network which is the first half will compress the image
we go from a very large image to smaller height but with greater volume.
So we loose a lot of spatial information because of the dimension cut, but it's much deeper.
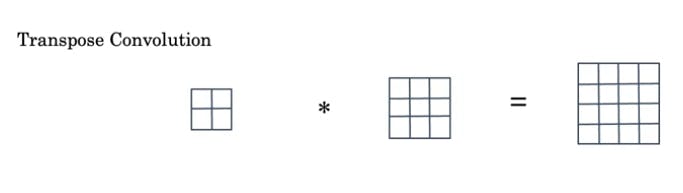
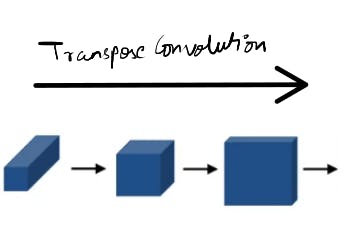 transpose convolution lets you take a small input, let's say 2x2 and blow it up into larger output say 4x4 by using a filter of size larger than the input.
This is the key building block of the U-Net architecture
transpose convolution lets you take a small input, let's say 2x2 and blow it up into larger output say 4x4 by using a filter of size larger than the input.
This is the key building block of the U-Net architecture
U-Net Architecture
