eBPF Technology: Everything You Need to Know

eBPF is a revolutionary kernel technology that allows developers to write custom code that can be loaded into the kernel dynamically, changing the way the kernel behaves. This enables a new generation of highly performant networking, observability, and security tools.
Just a few of the things you can do with eBPF include:
• Performance tracing of pretty much any aspect of a system
• High-performance networking, with built-in visibility
• Detecting and (optionally) preventing malicious activity
Why eBPF?
The Linux Kernel
To understand eBPF you’ll need a solid grasp of the difference between the kernel and user space in Linux. The Linux kernel is the software layer between your applications and the hardware they’re running on. Applications run in an unprivileged layer called user space, which can’t access hardware directly. Instead, an application makes requests using the system call (syscall) interface to request the kernel to act on its behalf. That hardware access can involve reading and writing to files, sending or receiving network traffic, or even just accessing memory. The kernel is also responsible for coordinating concurrent processes, enabling many applications to run at once.
As application developers, we typically don’t use the system call interface directly, because programming languages give us high-level abstractions and standard libraries that are easier interfaces to program. As a result, a lot of people are blissfully unaware of how much the kernel is doing while our programs run. If you want to get a sense of how often the kernel is invoked, you can use the strace utility to show all the system calls an application makes. Because applications rely so heavily on the kernel, it means we can learn a lot about how an application behaves if we can observe its interactions with the kernel. With eBPF we can add instrumentation into the kernel to get these insights. For example, if you are able to intercept the system call for opening files, you can see exactly which files any application accesses. But how could you do that interception? Let’s consider what would be involved if we wanted to modify the kernel, adding new code to create some kind of output whenever that system call is invoked.
Dynamic Loading of eBPF Programs
eBPF programs can be loaded into and removed from the kernel dynamically. Once they are attached to an event, they’ll be triggered by that event regardless of what caused that event to occur. For example, if you attach a program to the syscall for opening files, it will be triggered whenever any process tries to open a file. It doesn’t matter whether that process was already running when the program was loaded. This is a huge advantage compared to upgrading the kernel and then having to reboot the machine to use its new functionality. This leads to one of the great strengths of observability or security tooling that uses eBPF—it instantly gets visibility over everything that’s happening on the machine. In environments running containers, that includes visibility over all processes running inside those containers as well as on the host
What is eBPF?
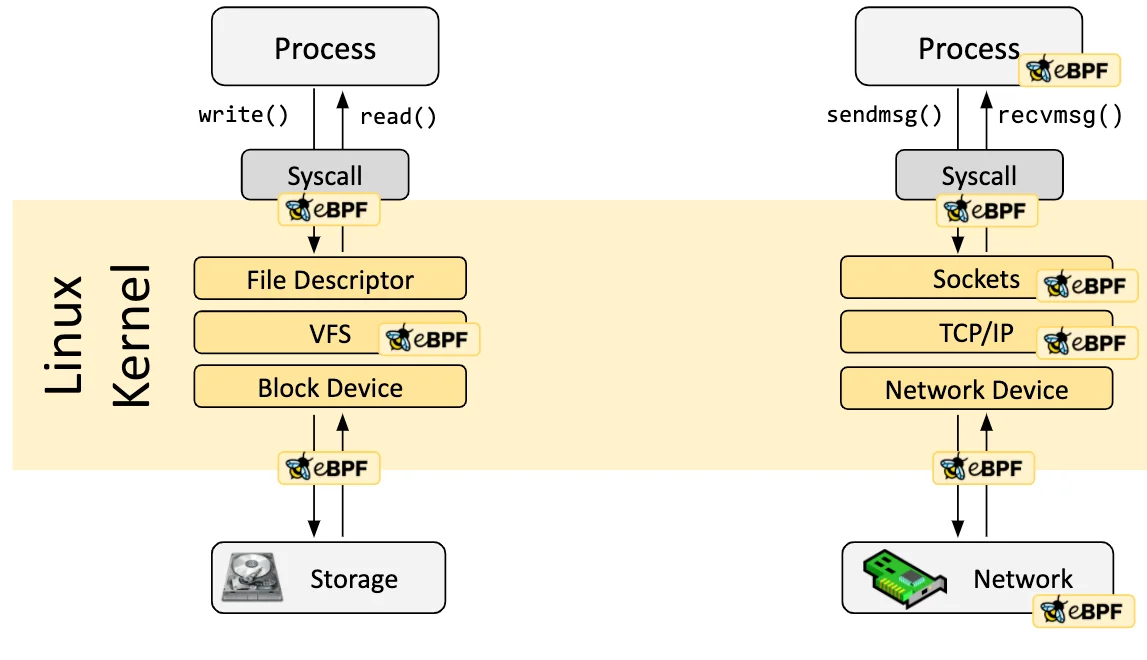
eBPF programs are event-driven and are run when the kernel or an application passes a certain hook point.
1.Pre-defined hooks include system calls, function entry/exit, kernel tracepoints, network events, and several others.
2.Custom hook :If a predefined hook does not exist for a particular need, it is possible to create a kernel probe (kprobe) or user probe (uprobe) to attach eBPF programs almost anywhere in kernel or user applications.
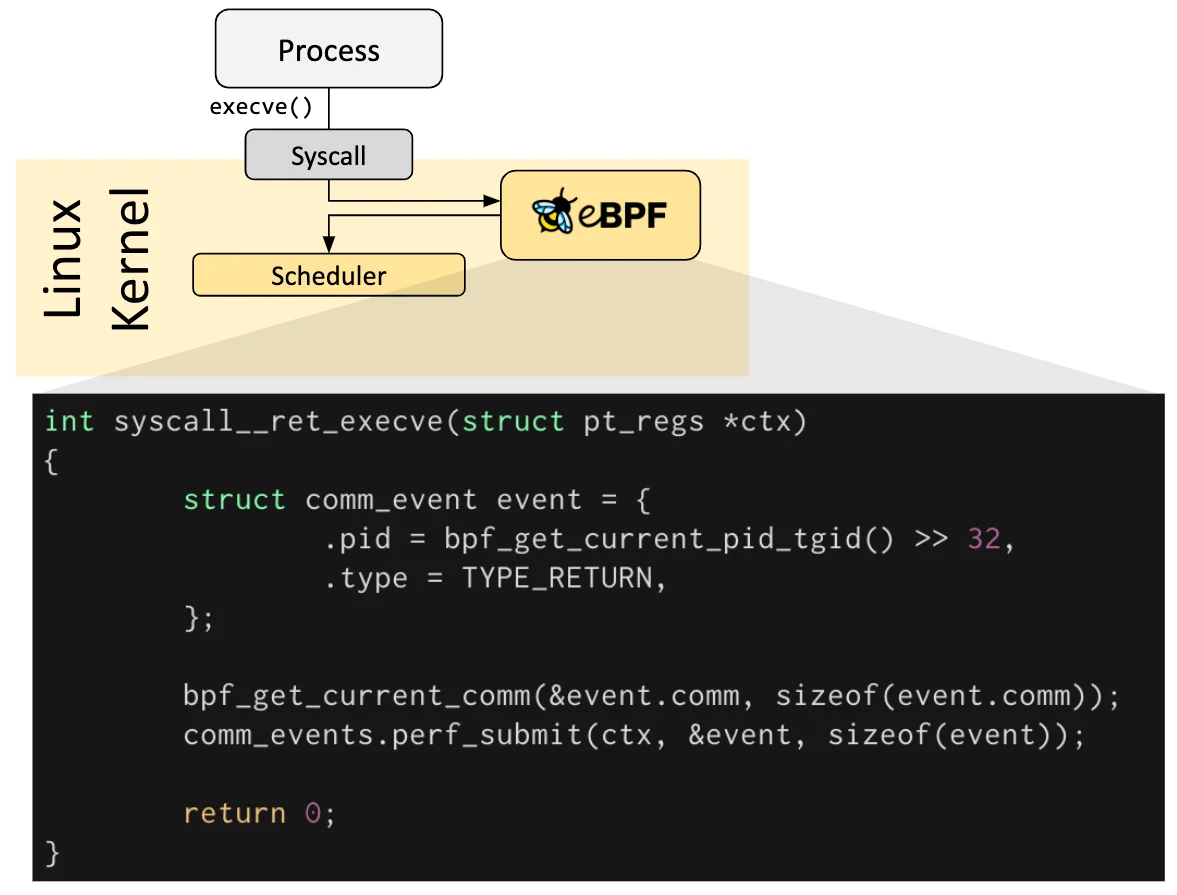
Figure. eBPF prog attached to Pre-defined syscall hook
Limitations of eBPF programming over Native C programming:
You can't use C library functions in the kernel; you need to create your own utility if needed.
eBPF C: In eBPF, you cannot use dynamic memory allocation or standard library functions like strlen or strcmp. For instance, in your eBPF code, you manually iterate over characters to find the last dot in a filename string, which is a common operation in native C code that could easily use strrchr or similar functions.
static inline void extract_file_extension(const char *filename, char* extension) { int len = bpf_core_read_str(extension, EXT_LEN, filename); if (len <= 0 || len >= EXT_LEN) { // Handle error or set a default value for extension return; } // Find the last dot in the filename int dot_index = -1; int i = len - 1; while (i >= 0) { char c; if (bpf_probe_read_kernel(&c, sizeof(c), (void *)(filename + i))) { // Handle error or break the loop break; } if (c == '.') { dot_index = i; break; } i--; } if (dot_index != -1) { // Found the dot, manually move the extension part to the beginning of the buffer int ext_len = len - dot_index - 1; for (int j = 0; j < ext_len; j++) { char c; if (bpf_probe_read_kernel(&c, sizeof(c), (void *)(filename + dot_index + 1 + j))) { // Handle error or break the loop break; } extension[j] = c; } extension[ext_len] = '\0'; // Null-terminate the extension } else { // No dot found, set a default value for extension extension[0] = '\0'; } }Native C:
Native C code that could easily use strrchr or similar functions.
const char* get_file_extension(const char* filename) { const char* dot = strrchr(filename, '.'); if (dot!= NULL) { dot++; return dot; } return ""; }
No Standard I/O Operations:
Native C: Can perform file I/O operations using standard library functions like fopen, fclose, etc.
eBPF C: Cannot perform file I/O operations directly but relies on kernel data structures and helper functions to operate within the kernel's context.
Limited Access to Kernel Data Structures:
Native C: Can directly access and modify global variables or data structures defined in the application.
eBPF C: Accesses kernel data structures through helper functions like
bpf_probe_read_kerneland uses BPFmapsfor shared state across different eBPF programs or instances
No Direct System Calls:
Native C: Makes direct system calls to the kernel using syscall() or similar mechanisms.
eBPF C: Does not make direct system calls. Instead, interacts with the kernel through predefined helper functions provided by the eBPF framework.
Size Limitations:
Native C: There are no practical size limitations on the executable size.
eBPF C: The entire eBPF program must fit within a small size limit (typically around 4KB to 8KB), which affects the complexity of the code that can be written.
No Error Handling:
Native C: Uses standard error handling mechanisms like errno, perror, etc., to manage errors.
eBPF C: Limited error handling options. Errors during operations like bpf_probe_read_kernel are checked, but the handling is basic and lacks the granularity of error handling in native C.
Concurrency and Synchronization:
- Native C: Supports multithreading and concurrency, allowing for parallel execution of code blocks.
eBPF C: Runs in a single-threaded environment within the kernel, meaning it cannot perform concurrent operations or synchronization tasks in the same way as a native C program running in user space.
https://nakryiko.com/posts/bpf-core-reference-guide/
I would highly suggest everyone to look Andrii Nakryiko's Blog, currently working on all things BPF, both in Linux kernel and in the user-space (libbpf, BPF CO-RE).



